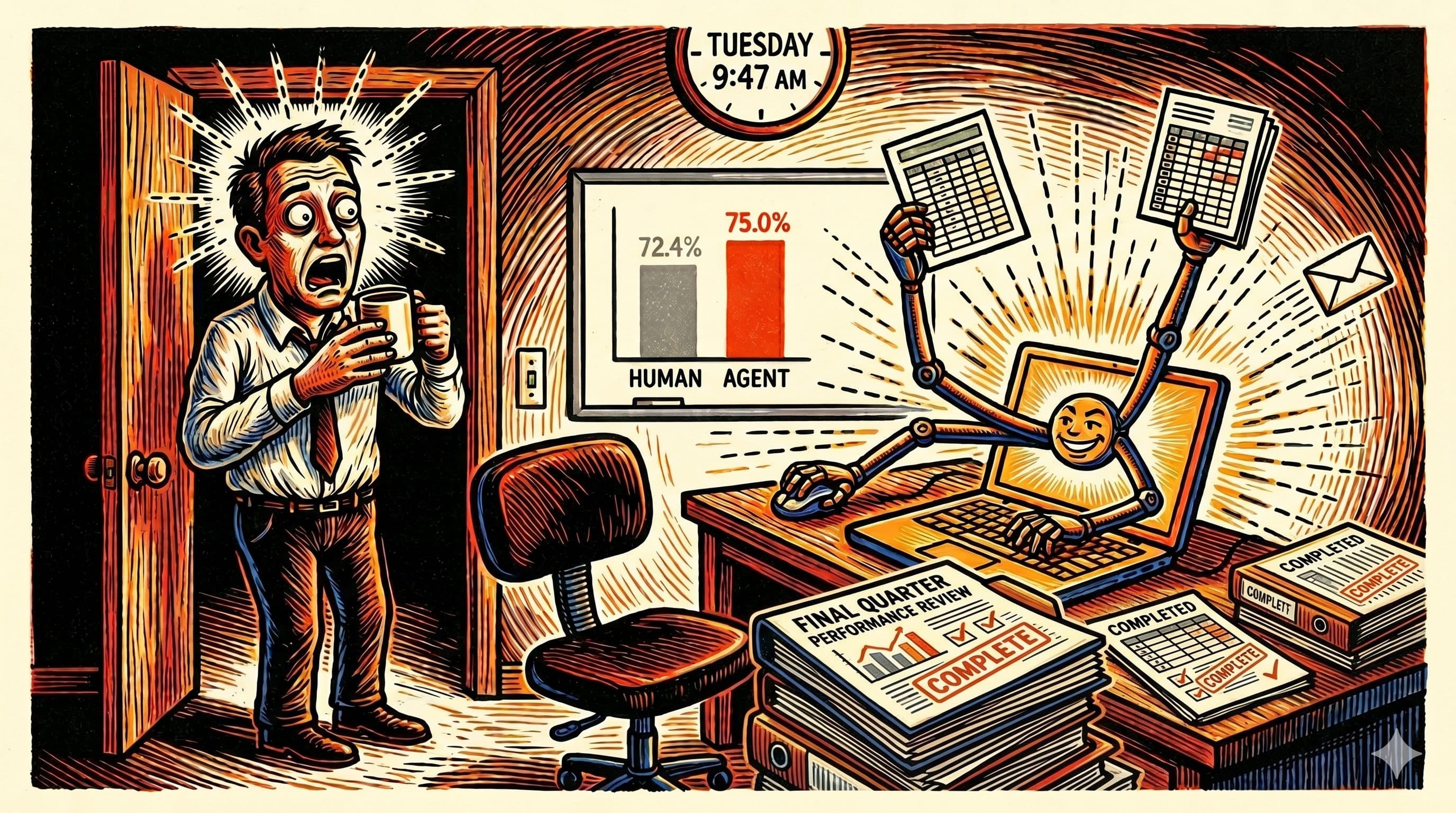
OpenAI's GPT-5.4, released on 5 March 2026, scored 75.0% on the OSWorld-Verified benchmark. The average human scored 72.4%. The benchmark asks a straightforward question: can the model open a real operating system and finish a real task, the way you would on a Tuesday morning.
For the first time, a general-purpose AI model answered yes, by a margin that is not a rounding error.
Three points above average is not a revolution. It is, however, the threshold where the conversation shifts from "can agents drive a computer" to "for which tasks do agents drive a computer better than I will, given the pay rate and the time of day."
What OSWorld actually tests
OSWorld-Verified is 369 tasks across Ubuntu, Windows, and macOS. The agent is handed a screenshot, a natural-language goal, and a mouse. It has to navigate the real UI of real applications: Excel, Google Sheets, Figma, file managers, terminals, IDEs, browsers. It has to open files, run code, cross-check results, update documents, and finish the job without a human closing the loop at each step. An execution-based grader then checks whether the goal was actually achieved, not whether the output looked plausible.
This matters because most AI benchmarks measure fluency. OSWorld measures whether the thing got done.
The size of the jump
GPT-5.4's immediate predecessor, GPT-5.2, scored 47.3% on the same benchmark. GPT-5.4 scored 75.0%. That is a 27.7 point jump in a single release cycle. If you are accustomed to AI benchmark curves that look like gentle slopes, this one looks more like the kind of line that makes someone late for a board meeting.
Context matters here. Claude Opus 4.6 had narrowly crossed the human baseline in February at 72.7%. UiPath's Screen Agent, running on Claude Opus 4.5, had topped the leaderboard in January. The GPT-5.4 result confirms what the shape of those earlier lines predicted: a general-purpose frontier model, released with native computer use built in, clears the bar by a usable margin rather than a statistical one.
What makes the result practically interesting, rather than narrowly benchmark-relevant, is the 1.05 million token context window. Agents that operate your screen produce enormous amounts of intermediate state: screenshots, DOM snapshots, tool call results, partial transcripts. A million tokens is roughly 2,100 pages. That is enough working memory to keep an entire day of screens, decisions, and reasoning in a single uninterrupted pass, which is exactly what long agentic workflows need.
The caveat most coverage missed
Epoch AI published an analysis of OSWorld that most of the launch coverage skipped over. About 15% of OSWorld tasks require only a terminal, not a graphical interface at all. Another 30% can be solved by substituting terminal commands and Python scripts for the intended GUI actions. Agents with code execution available can route around the graphical interface for nearly half the benchmark.
This does not invalidate the result. The tasks that can be solved via terminal are still real tasks, and the agent still has to choose the right path and verify the outcome. It does mean the real-world pure-GUI performance gap is wider than 2.6 points, and the distinction matters if your use case is "agent opens Excel" rather than "agent writes a Python script that happens to produce the same answer."
The benchmark result is a real milestone. It is also not quite the milestone some headlines claimed. Both things can be true without contradiction.
The practitioner playbook
For anyone actually trying to use these agents in working hours, none of this changes the order in which work should be handed to them. It changes the list of things worth trying.
What to hand over first
Three categories are now ripe for delegation. Start here:
- Repetitive, well-documented workflows where the desired output can be described without ambiguity. Filing expense receipts. Converting files from one format to another. Populating a dashboard from a CSV. These tasks have clear success criteria and tolerate slight variance in approach.
- Research and assembly work where the agent can browse, gather, and format, but a human checks the output before it matters. The agent is doing the 80% that is mechanical. You are doing the 20% that is judgment.
- Cross-application glue tasks that span two or three tools without a good built-in integration. Moving structured data between a notes app and a spreadsheet. Triaging a shared drive. Converting meeting notes into calendar invites.
The common thread: the task is repeatable, the output is checkable, and the cost of a mistake is a retry rather than a phone call.
What to guard carefully
Three categories are not ready, regardless of benchmark scores:
- Anything with irreversible effects and limited audit trail. Sending emails, making bookings, submitting forms, moving money. Not because the agent cannot do these. Because the failure mode when it does them wrong is a conversation with another human, not a second attempt.
- Judgment calls disguised as workflows. "Reply to the customer" is a judgment call dressed as a task. The shape of the output matters less than the shape of the decision, and the decision is where humans still add the most value.
- Anything involving sensitive data with access beyond the agent's scope. If the agent can read your email, it can read all of your email. Decide in advance which threads are in scope and give the agent a surface that enforces the boundary, rather than a hope that it will interpret the boundary correctly.
Designing for graceful handoff
The agent will get stuck. Design for when, not if:
- Checkpoint often, write to disk. Agents that cannot be resumed mid-workflow are agents that must repeat work when they hit a problem. Save intermediate state where a human can see it and pick up without starting over.
- Fail loudly, not silently. An agent that quietly produces a slightly wrong result is more expensive than an agent that stops and asks. Build the loud failure in from the start. Retrofitting it after a bad outcome is where most of the pain lives.
- Bound the blast radius. The smallest number of tools, the narrowest scopes, the shortest sessions that still accomplish the task. If the agent starts doing something surprising, surprising should mean interesting, not catastrophic.
An agent that quietly produces a slightly wrong result is more expensive than an agent that stops and asks.
Why the governance gap makes the personal playbook sharper
The broader picture sharpens the individual case. Deloitte's 2026 State of AI in the Enterprise found that only 21% of organisations planning agentic AI deployment report mature governance frameworks. Gartner projects that more than 40% of agentic AI projects will be cancelled by the end of 2027, with most failures traced to escalating costs, unclear business value, or governance infrastructure that never caught up with ambition.
Taken together, these figures describe an environment in which many organisations will spend the next eighteen months deploying agents into production, discovering failure modes the hard way, and rolling back. The ones that navigate this well will not be the ones with the largest model budgets. They will be the ones where individuals have actually used these tools on their own work, long enough to develop intuition for where the agent is trustworthy and where it is not.
That intuition is not free. It comes from running agents on real tasks, being unsurprised when they fail in unexpected ways, and keeping a written record of the patterns. The professionals building this muscle now are doing cheap learning. The professionals building it during a procurement review are doing expensive learning.
What 2.6 points actually changed
The 2.6 percentage points matter because they are the margin by which a general-purpose agent now beats the average person at using a computer. The agent still cannot use the computer as well as a skilled professional can. It can, however, use the computer well enough that the question is no longer "will this work at all." The question is which tasks are worth the trade.
The OpenAI release notes say the same thing in different language: GPT-5.4 is the first mainline model with native computer-use capability, not an experimental side branch. OpenAI did not release a demo. They released a general-purpose model where desktop operation is simply one of the things the model does, alongside writing, coding, and analysis. That framing is the actual shift. Computer use is no longer a niche capability that lives in a separate product. It is part of the default toolkit.
For the Artificial Leverage reader, the practical implication is narrower and more useful than the headlines suggest. Start with one repetitive task in your week. Delegate it to an agent. Watch where it struggles. Write down what you learn. Do the next one. The benchmarks will keep moving. The people who get value out of them will be the ones who were already running small agents on real work when the next number dropped.
The pilot phase is over for the benchmarks. The question is whether it is over for your workflow.
Sources
- OpenAI, Introducing GPT-5.4, 5 March 2026
- XLANG Lab, Introducing OSWorld-Verified, July 2025
- Xie et al., OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments, NeurIPS 2024
- Greg Burnham, What does OSWorld tell us about AI's ability to use computers?, Epoch AI
- TechCrunch, OpenAI launches GPT-5.4 with Pro and Thinking versions, 5 March 2026
- Fortune, OpenAI launches GPT-5.4, its most powerful model for enterprise work, 5 March 2026
- Deloitte, State of AI in the Enterprise 2026
- Gartner, 40%+ of agentic AI projects will be cancelled by end-2027, June 2025